AMD RDNA 4 architecture GPUs
AMD RDNA™ 4 architecture GPUs, which have 3rd-generation Matrix Cores, improved the performance of Generalized Matrix Multiplication (GEMM) operations. The table below compares theoretical FLOPS/clock/CU (floating point operations per clock, per compute unit) to previous generations. However, we changed the VGPR layout for the arguments of Wave Matrix Multiply Accumulate (WMMA) operations compared to the previous RDNA 3 generation [1]. Therefore, it does not have backward compatibility. In order to accelerate GEMM operations on RDNA 4 GPUs, we need to use the new intrinsics added for GPUs of this generation. In this post, we explain how to use matrix cores on RDNA 4 GPUs from a HIP kernel.
| AMD Radeon™ RX 6950 XT (RDNA 2) | AMD Radeon™ RX 7900 XTX (RDNA 3) | AMD Radeon™ RX 9070 XT (RDNA 4) | |
|---|---|---|---|
| FP16 | 256 | 512 | 1024 |
| BF16 | N/A | 512 | 2048 |
| I8 | 512 | 512 | 2048 |
Wave Matrix Multiply Accumulate (WMMA) on AMD RDNA 4
Before going into the detail of the AMD RDNA 4 architecture implementation, let’s do a refresher on the matrix operation. A GEMM operation can be written as follows:
WMMA operates on matrices of 16×16 dimension only. Thus, if the matrix we are working on is smaller than that, the matrices need to be padded. If the matrix is larger than that, we can still use WMMA intrinsics by decomposing the larger matrix into GEMM operations of 16×16 matrices.
This GEMM operation can be implemented easily in a kernel. A single lane of a wavefront simply allocates multiple 16×16 matrices in VGPR, loads them into the VGPRs, and then just executes the operation. If this operation is executed in all the lanes in a wavefront, it’s obviously very inefficient because they all load the same matrices. WMMA changes it and simplifies the operation. The WMMA intrinsic is different from other operations we do in a HIP kernel. Instead of writing code for each lane in a wavefront, it is required to write code to use the entire wavefront.
First, it changes the VGPR allocation. Instead of allocating the entire matrix in a single lane, each lane allocates smaller VGPRs to store part of the matrix. This reduces VGPR pressure. The other point is that once the matrices are loaded into VGPRs, a WMMA intrinsic is called from all the lanes in a wavefront, which triggers the execution of the GEMM operation in the matrix core.
There are a few WMMA intrinsics, but here in this blog, we focus on the WMMA intrinsic taking A, B as 16-bit floating-point numbers, and D, C as 32-bit floating-point numbers, which is __builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12.
Using WMMA intrinsics
There are a few WMMA intrinsics for AMD RDNA 4 architecture GPUs. They have postfix _gfx12, which did not exist for the WMMA intrinsics for RDNA 3 or gfx11 generation. It expects the same format for A, B matrices and C, D matrices. These formats are included in the name of the intrinsic like this:
__builtin_amdgcn_wmma_
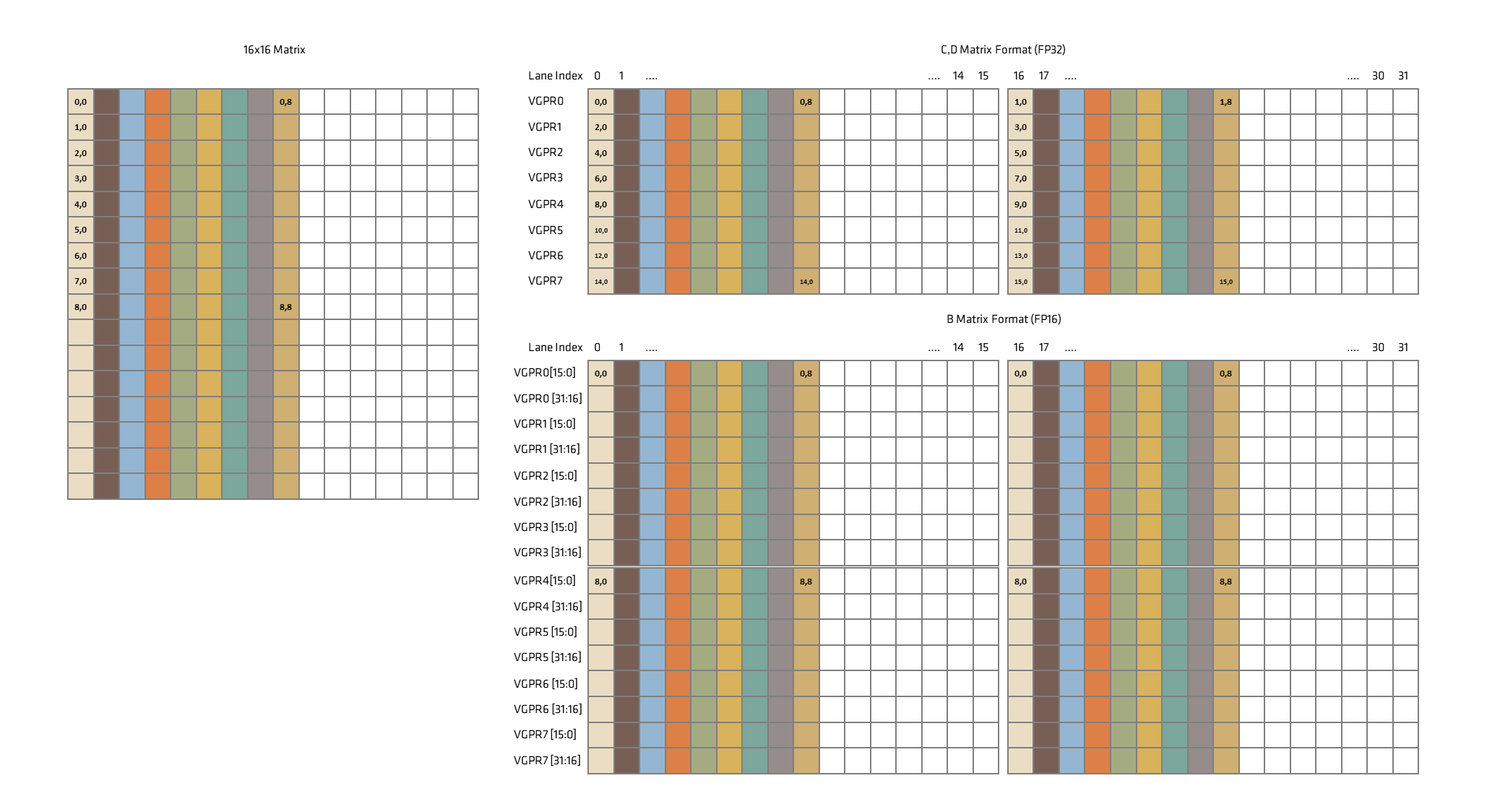
Therefore, the intrinsic above uses 32-bit float for C, D, while 16-bit float is used for A and B. How 16×16 matrix is mapped to VGPRs in each lane in a wavefront is illustrated below,
In the AMD RDNA 3 architecture, we needed to duplicate some elements for A and B, but it is removed for RDNA 4, which makes the layout simpler in VGPRs. Each lane only needs to load (or store) 8 elements of a matrix. Here a wavefront consists of 32 lanes, single wavefront loads matrix exactly once . One thing to note is that B, C, and D matrices are row major while A is transposed thus column major as shown in the figure above. Now let’s look at the example code below.
extern "C" __global__ void wmma_matmul( __fp16* a, __fp16* b, __fp16* c )
const int WMMA_DATA_WIDTH = 8;
const int laneWrapped = threadIdx.x % 16;
const int laneGroup = threadIdx.x / 16;
for( int ele = 0; ele < WMMA_DATA_WIDTH; ++ele )
b_frag[ele] = b[16 * ( ele + laneGroup * WMMA_DATA_WIDTH ) + laneWrapped];
a_frag[ele] = a[16 * laneWrapped + ( ele + laneGroup * WMMA_DATA_WIDTH )];
c_frag = __builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12( a_frag, b_frag, c_frag );
for( int ele = 0; ele < WMMA_DATA_WIDTH; ++ele )
c[16 * ( ele + laneGroup * WMMA_DATA_WIDTH ) + laneWrapped] = c_frag[ele];
With this instruction, A and B matrices are 16-bit float. There is an intrinsic we can use to convert and pack two 32-bit floats into a single 32-bit VGPR, which helps the compiler compared to converting one by one for 32-bit float inputs. This is suitable for converting 32-bit float matrix to 16-bit float matrix, especially in contexts like matrix multiplication chains.
__device__ half_2 packFp32s( float a, float b ) { return __builtin_amdgcn_cvt_pkrtz( a, b ); }
The load of A, B matrices can be written as shown in below with this function .
half_2* a_ptr = reinterpret_cast<half_2*>( &a_frag );
half_2* b_ptr = reinterpret_cast<half_2*>( &b_frag );
for( int ele = 0; ele < WMMA_DATA_WIDTH / 2; ++ele )
const int e0 = ele * 2 + 0, e1 = ele * 2 + 1;
b_ptr[ele] = packFp32s( b[16 * ( e0 + laneGroup * WMMA_DATA_WIDTH ) + laneWrapped], b[16 * ( e1 + laneGroup * WMMA_DATA_WIDTH ) + laneWrapped] );
a_ptr[ele] = packFp32s( a[16 * laneWrapped + ( e0 + laneGroup * WMMA_DATA_WIDTH )], a[16 * laneWrapped + ( e1 + laneGroup * WMMA_DATA_WIDTH )] );
Full source code including host program using Orochi can be found here.
Transitioning from AMD RDNA 3 WMMA to RDNA 4 WMMA
As briefly mentioned above, the VGPR format for WMMA has been changed since the AMD RDNA 3 architecture. The VGPR format of RDNA 4 is much simpler than the one of RDNA 3 which is illustrated below. We can see that C and D matrices are split into even and odd for lower 16 lanes and upper 16 lanes. Therefore, in order to convert D matrix to B matrix to chain WMMA operations as we do for MLP we will explain shortly, data needs to be shuffled among lanes in RDNA 3. This is not needed for RDNA 4.
Implementing a simple MLP
With WMMA operation, we can implement a fully connected neural network called MLP easily. Here we assume the input dimension is 16, the number of internal neurons is 16, and the output dimension is 16 for simplicity. The inference execution of an MLP can be written as
This can be mapped into WMMA intrinsic twice. For the first equation, we need to load all the values for the weight matrix , input data , and bias matrix . For the second equation, we only need to load , and use the output from the first equation as B in eqn. 1. Here we need to be careful as the format of D and B matrices in eqn. 1 are different. When __builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12 is used, the D matrix is 32-bit float while the C matrix is 16-bit float. Although we need downcasts, note that we do not need any data exchange among lanes, since matrix D and B have the same layout, except for the floating-point data type. The kernel below is an example of the MLP. Note that we dropped bias term () for simplicity.
extern "C" __global__ void minimumMlp( __fp16* w, __fp16* x, __fp16* cOut )
const int WMMA_DATA_WIDTH = 8;
const int laneWrapped = threadIdx.x % 16;
const int laneGroup = threadIdx.x / 16;
for( int ele = 0; ele < WMMA_DATA_WIDTH; ++ele )
b_frag[ele] = x[16 * ( ele + laneGroup * WMMA_DATA_WIDTH ) + laneWrapped];
a_frag[ele] = w[16 * laneWrapped + ( ele + laneGroup * WMMA_DATA_WIDTH )];
c_frag = __builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12( a_frag, b_frag, c_frag );
// move pointer for the weight matrix
for( int ele = 0; ele < WMMA_DATA_WIDTH; ++ele )
// convert C matrix to B matrix
b_frag[ele] = c_frag[ele];
a_frag[ele] = w[16 * laneWrapped + ( ele + laneGroup * WMMA_DATA_WIDTH )];
c_frag = __builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12( a_frag, b_frag, c_frag );
for( int ele = 0; ele < WMMA_DATA_WIDTH; ++ele )
cOut[16 * ( ele + laneGroup * WMMA_DATA_WIDTH ) + laneWrapped] = c_frag[ele];
Conclusion
In this article, we explained how to use WMMA intrinsics on AMD RDNA 4 architecture GPUs. We also showed how to implement an MLP inference using WMMA intrinsics. What we did not cover in this article is application to GEMM operations with larger matrices, which we leave as an exercise for the readers. Further information can be found in the AMD ISA guide [2].
References
- How to accelerate AI applications on AMD RDNA 3 using WMMA, 2023
- “AMD RDNA 4” Instruction Set Architecture Reference Guide, 2025

{kind=link}